Knowledge AI¶
![]()
Note
- You are subject to the terms of the Generative AI model providers to which you are connecting. Cognigy cannot take responsibility for your use of third-party services, systems, or materials.
- If you are an existing Cognigy customer, the performance timelines (SLA) specified in your contract do not apply to the trial version of Knowledge AI.
Knowledge AI can be used to enhance Natural Language Processing (NLP) and Conversational AI. The primary goal of Knowledge AI is to enable these systems to access and comprehend a vast amount of information from different formats, such as documents, articles, manuals, FAQs, and more. By accessing and understanding knowledge bases, these AI systems can provide more accurate, context-aware, and helpful responses to user queries.
With the Cognigy Knowledge AI solution, you no longer need to rely solely on Intents and Default Replies to identify user questions and provide relevant content based on predefined responses. Crafting these question-and-answer pairs can be time-consuming and labor-intensive, requiring ongoing maintenance efforts.
Instead, Cognigy Knowledge AI lets you upload existing knowledge as documents in various formats, including PDF, text, PPTX and DOCX, as well as files in the Cognigy CTXT format and Web Pages. This technology extracts meaningful information from these documents and makes it accessible to Flow designers via the Knowledge AI Nodes. This approach empowers you to build knowledge-based AI Agents quickly and effortlessly, bypassing the limitations of traditional intent-based systems and simplifying the process of creating sophisticated conversational experiences.
Prerequisites¶
Before using this feature, follow these steps:
- Apply for a license and allocate quotas.
-
Create an account in one of the LLM Providers:
- OpenAI. You need to have a paid account or be a member of an organization that provides you access. Open your OpenAI user profile, copy the existing API Key, or create a new one and copy it.
- Microsoft Azure OpenAI. You need to have a paid account or be a member of an organization that provides you access. Ask your Azure Administrator to provide API Key, resource name, and deployment model name.
For the Knowledge AI case, you need the
text-embedding-ada-002model. However, if you intend to transform the Knowledge Search result and output it, you will also need an additional model from the LLM Prompt Node & Search Extract Output Node column in the supported models list.
Create a Knowledge Store¶
You can create a preconfigured knowledge store. To do this, follow these steps:
- Open the Cognigy.AI interface.
- In the left-side menu, select Knowledge. The Knowledge AI wizard will be opened.
- Continue following the wizard instructions.
-
Specify a unique name and select an embedding model.
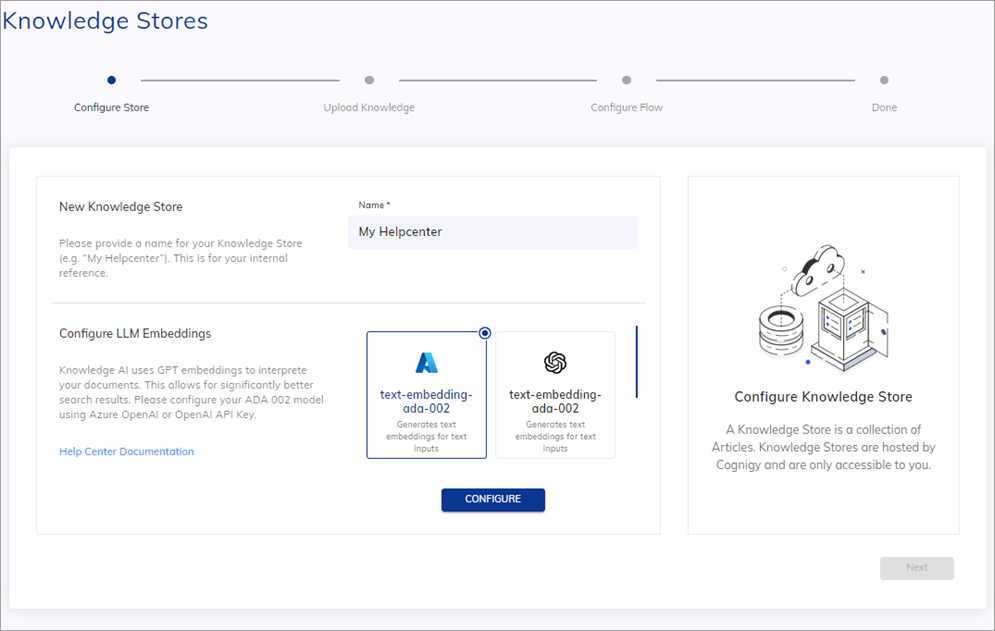
-
Click Configure and enter credentials for the model:
- Connection name — create a unique name for your connection.
- apiKey — add an Azure API Key. This value can be found in the Keys & Endpoint section when examining your resource from the Azure portal. You can use either
KEY1orKEY2. - Resource Name — add a resource name. To find this value, go to the Microsoft Azure home page. Under Azure services, click Azure OpenAI. In the left-side menu, under the Azure AI Services section, select Azure Open AI. Copy the desired resource name from the Name column.
- Deployment Name — add a deployment name. To find this value, go to the Microsoft Azure home page. Under Azure services, click Azure OpenAI. In the left-side menu, under the Azure AI Services section, select Azure Open AI. Select a resource from the Name column. On the resource page, go to Resource Management > Model deployments. On the Model deployments page, click Manage Deployments. On the Deployments page, copy the desired deployment name from the Deployment name column.
- Api Version — add an API version. The API version to use for this operation in the
YYYY-MM-DDformat. Note that the version may have an extended format, for example,YYYY-MM-DD-preview. - Custom URL — this parameter is optional. To control the connection between your clusters and the Azure OpenAI provider, you can route connections through dedicated proxy servers, creating an additional layer of security. To do this, specify the URL in the following pattern:
https://<resource-name>.openai.azure.com/openai/deployments/<deployment-name>/completions?api-version=<api-verson>. When a Custom URL is added, the Resource Name, Deployment Name, and API Version fields will be ignored.
- Connection name — create a unique name for your connection.
- apiKey — add an API Key from your OpenAI account. You can find this key in the User settings of your OpenAI account.
- Custom Model — this parameter is optional. Add the particular model you want to use. This parameter is helpful when you have multiple types of models on the LLM provider side and intend to utilize a specific model type. For example, if you have GPT-4, you can specify
gpt-4-0613for your use case. When a custom model is added, the default LLM Model will be ignored. For more information about provider's models, refer to the OpenAI documentation.
- Connection name — create a unique name for your connection.
- Token — specify a key that you created in your Aleph Alpha account.
- Custom URL — this parameter is optional. To control the connection between your clusters and the Aleph Alpha provider, you can route connections through dedicated proxy servers, creating an additional layer of security. To do this, specify the base URL, for example:
https://api.aleph-alpha.com.
- Connection name — create a unique name for your connection.
-
Click Next.
- Download the cognigy-sample.ctxt file in the
.ctxtformat. - In the Upload Knowledge step, select the Cognigy CTXT type and upload the saved file, then click Next. The knowledge source will get the same name as the file name. If you want to upload a different file from the one mentioned at step 7, note that the file name can have a maximum length of 200 symbols, must not start or end with spaces, and cannot contain the following characters:
/ \ : * ? " < > | ¥. - (Optional) In the Configure Answer Extraction Model section, select the additional model if you want to extract key points and output the search result as text or adaptive card. Click Configure and enter model credentials.
- (Optional) When the additional model is configured, click Create Flow. A Flow with the Search Extract Output Node will be created.
- Click Next.
To learn more about ctxt, refer to Cognigy Text Format.
Explore a Knowledge AI project¶
Working with Knowledge AI involves two phases similar to how one would work with Intents. The first phase is ingesting and preparing knowledge, and the second phase is querying the knowledge during runtime.
First phase:
- Raw Information Upload. Cognigy.AI receives access to raw information via uploaded files that contain knowledge.
- Knowledge Chunk Extraction. A collection of tools that extracts text and metadata from the raw information. Chunks are accessible for modification in the Chunk Editor.
- Vectorization. The text of Knowledge Chunks is encoded into numeric representations using an Embedding machine learning model. Embeddings are high-dimensional vectors that encode word meaning and similarity into numeric representations. Cognigy.AI stores these vectors in a specialized internal database for quick access during runtime.
Second phase:
- Knowledge Base Querying. During runtime, the Knowledge AI system can query the knowledge base to provide accurate and contextually appropriate responses to user queries.
- Knowledge-based AI Agents Building. AI Agents utilize the knowledge stored in the Knowledge Base to engage in more sophisticated and intelligent conversations with users. These agents can provide context-aware responses based on the information extracted from the uploaded files.
Knowledge AI Management¶
Knowledge is organized in a hierarchy of stores, sources, and chunks to enable accurate responses by the system. These hierarchical structures are described below.
Knowledge Store¶
A Knowledge Store is a container that holds and organizes multiple Knowledge Sources. It provides a centralized and structured environment for managing and categorizing various sources of knowledge. The Knowledge Store helps streamline the knowledge management process by grouping related Knowledge Sources, making it easier to organize, search, and retrieve relevant information during runtime.
You can also export and import a Knowledge Store as a Package.
The maximum number of stores per project is described in the Limitations section.

Knowledge Source¶
A Knowledge Source represents the output of transforming various types of content into a structured and accessible format. Each content type corresponds uniquely to a specific Knowledge Source, containing valuable knowledge in the form of user manuals, articles, FAQs, and other relevant information.
By breaking down the content of these sources into smaller units known as chunks, the Knowledge Source becomes a specific collection of organized and structured knowledge.
In addition to the main content, you can include other types of information, such as links and dates, in the metadata.
The following types of content are supported:
.ctxt(recommended).txt.pdf.docx.pptxweb page
With content parsers, you can handle a wider range of formats. For more details, read Text Extraction with Content Parsers.
The .ctxt (Cognigy text) format effectively splits the text into chunks and provides wide possibilities for working with metadata. For other formats, the results of file conversion may produce poorer outcomes.
The .pdf format has two chunk splitting strategies.
The maximum number of sources per store is described in the Limitations section.

Additionally, you can use Source Tags. These tags serve to refine the scope of your knowledge search, allowing you to include only the most pertinent sections of the knowledge base and, as a result, improve the accuracy of search outputs.
To apply these tags, specify them when uploading a source type. For the .ctxt format, you must include them in the source metadata, while for other formats, you need to specify them within the Cognigy.AI interface when creating a new knowledge source.
Source Tags
- The maximum number of tags per knowledge source is 10.
- A Source Tag cannot be modified after creating the source.
- A Source Tag cannot be added to already existing sources.
Chunk¶
A Chunk is a unit of knowledge extracted from a Knowledge Source. Chunks are smaller, self-contained pieces of information that the Knowledge AI system can process and manage effectively.
For instance, a chunk can represent a single paragraph, a sentence, or even a smaller unit of text from a document. By dividing the content into chunks, the system gains better granularity, enabling it to analyze and respond to user queries more efficiently. The extraction of knowledge into chunks enhances the system's ability to match the right information to user questions, resulting in more accurate and contextually appropriate responses.
Each chunk can have associated metadata. The number of meta-data key-value pairs is limited and supports only simple data types such as number, string, and boolean. The maximum number of Chunks as well as the maximum length of supported characters per Chunk are described in the Limitations section.

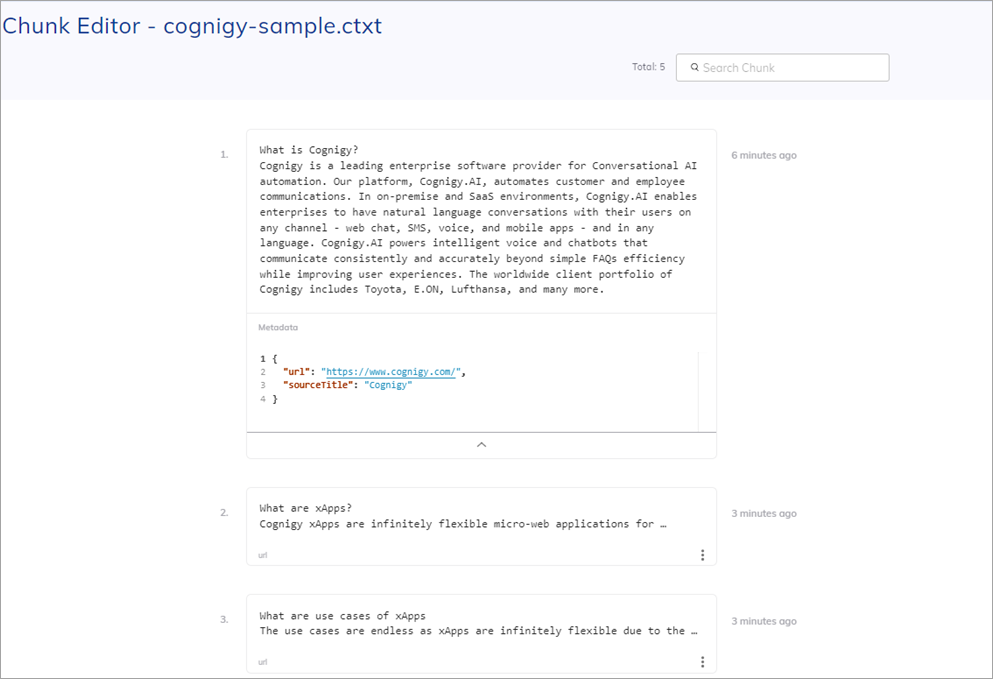
Chunk Editor¶
The Chunk Editor is a tool that helps you interact with and manage chunks. The Editor provides a user-friendly interface that enables you to manipulate the content within each chunk. Users can modify the text, add new information, delete sections, or rearrange the order of content to ensure the accuracy and relevance of the knowledge.
Search, Extract and Output Knowledge¶
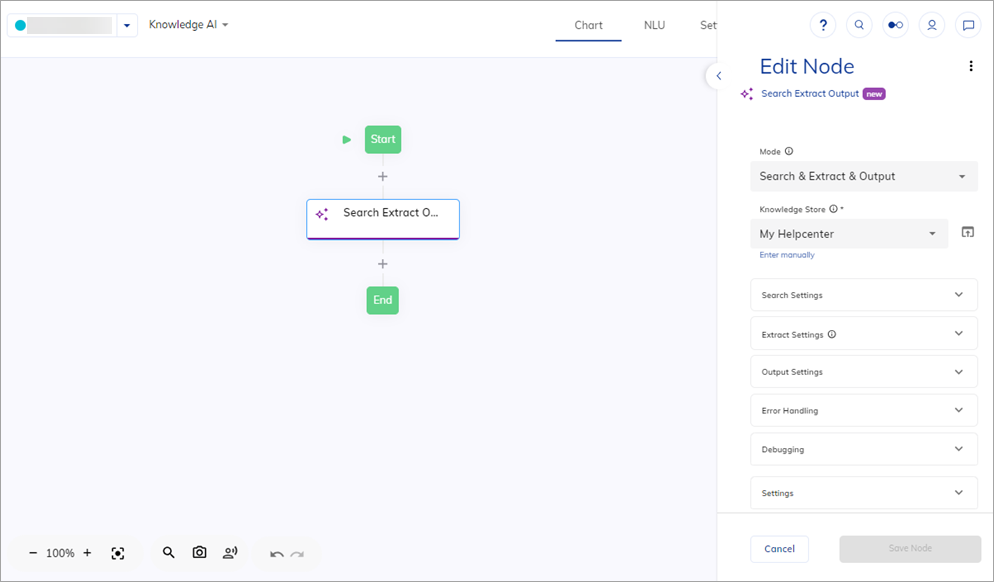
- Navigate to Build > Flows and create a new Flow.
- In the Flow editor, add a Search Extract Output Node.
- In the Node editor, select the knowledge store that you recently created.
-
Select one of the following modes:
- Search & Extract & Output — performs a knowledge search, extracts key points, and outputs the result as text or adaptive card. For this mode, you need models from the list of supported providers that cover both the
LLM Prompt Node & Search Extract Output NodeandKnowledge Searchcases. - Search & Extract — performs a knowledge search, extracts key points, but no automatic output. For this mode, you need models from the list of supported providers that cover both the
LLM Prompt Node & Search Extract Output NodeandKnowledge Searchcases. - Search only — performs a knowledge search and retrieves information without extraction or automatic output. For this mode, you only the
text-embedding-ada-002model.
- Search & Extract & Output — performs a knowledge search, extracts key points, and outputs the result as text or adaptive card. For this mode, you need models from the list of supported providers that cover both the
-
Check if Context-Aware Search is activated in the Search settings section. This feature considers the context of the transcript for the search, allowing an AI Agent to address follow-up questions. Be aware that this feature will consume LLM tokens on your LLM prover side.
- When the Context-Aware Search setting is enabled, configure the number of Transcript Steps. This setting affects the depth of context considered when retrieving search results.
- (Optional) In the Source Tags field, add tags by specifying each tag separately and pressing enter. Before specifying tags, ensure that they were provided during the upload of the source file for the selected knowledge source.
- Click Save Node.
- Proceed to the Interaction Panel and send the
Can Cognigy connect to a Contact Center?question.
You will receive a response generated from the absorbed Knowledge.
To learn more about the Search Extract Output Node, refer to the related article.
Limitations¶
The table below presents limitations. These limitations are subject to future changes by Cognigy.
| Description | Limit | Cognigy.AI Versions |
|---|---|---|
| Maximum number of Knowledge Stores per Project | 10 | Applicable to version 4.77 and earlier |
| Maximum number of Knowledge Sources per Store | 10 | Applicable to version 4.77 and earlier |
| Maximum file upload size for creating a Knowledge Source | 10 MB | All |
| Maximum number of source tags per Knowledge Source | 10 | All |
| Maximum number of source tags per Search Extract Output Node | 5 | All |
| Maximum number of Chunks per Knowledge Source | 1000 | All |
| Maximum number of Source metadata pairs | 20 | All |
| Maximum number of Chunk metadata pairs | 20 | All |
| Maximum number of characters for text per Chunk | 2000 | All |
| Maximum number of characters for metadata per Chunk | 1000 | All |
| Maximum number of characters for metadata per Source | 1000 | All |
Note
Knowledge AI specific objects, such as Stores, Sources and Chunks, are not a part of Cognigy.AI Snapshots. Instead, you can use Packages to import or export Knowledge Stores.
FAQ¶
Q1: Is Knowledge AI free of charge?
A1: Knowledge AI is not free of charge and requires a separate license.
Q2: I encountered a Request failed with status code 429 error while attempting to upload a file. How can I solve this issue?
A2: The 429 error occurs when your organization's rate limit is exceeded on the side of your LLM's provider. To learn more, refer to your provider's documentation. For instance, if you're using the OpenAI API, check out the article How can I solve 429: 'Too Many Requests' errors?.
Q3: I encountered a Error while performing knowledge search. Remote returned error: Search failed: Could not fetch embeddings due to missing API resource name for Azure OpenAI error while using knowledge search features. How can I solve this issue?
A3: In recent releases, we have updated the connection settings to Azure OpenAI LLMs and added new parameters, such as the Resource Name. If you have an older connection (for example, created in the 4.53 release) to Azure OpenAI LLMs, especially Azure OpenAI text-embedding-ada-002 for knowledge search features, you might encounter this error when an LLM is triggered. To resolve this issue, recreate the LLM and the connection so that both have the latest format.