

Key Benefits
- Rapid Quality Assessment. You can evaluate the NLU model’s effectiveness at a glance without extensive manual testing.
- Targeted Improvements. The Intent analyzer includes detailed scoring that highlights specific areas for refinement, thereby improving Intent recognition.
Restrictions
- After editing example sentences, the NLU model must be retrained to update scores.
- Strong overall Intent model scores don’t guarantee perfect individual Intents; red or yellow Intents may still need work.
- An Intent requires at least five example sentences. If trained with fewer, a negative feedback indicator will appear after the build, signaling that while the Intent still functions, its performance will be significantly reduced.
How to Set up
- In the Flow editor, go to NLU > Intents.
- Add a variety of example sentences into each Intent.
- In the upper-right corner, click Build Model to process the sentences and generate the initial model.
- View scores for the overall model, individual Intents, and example sentences.
Explore Intent Analyzer
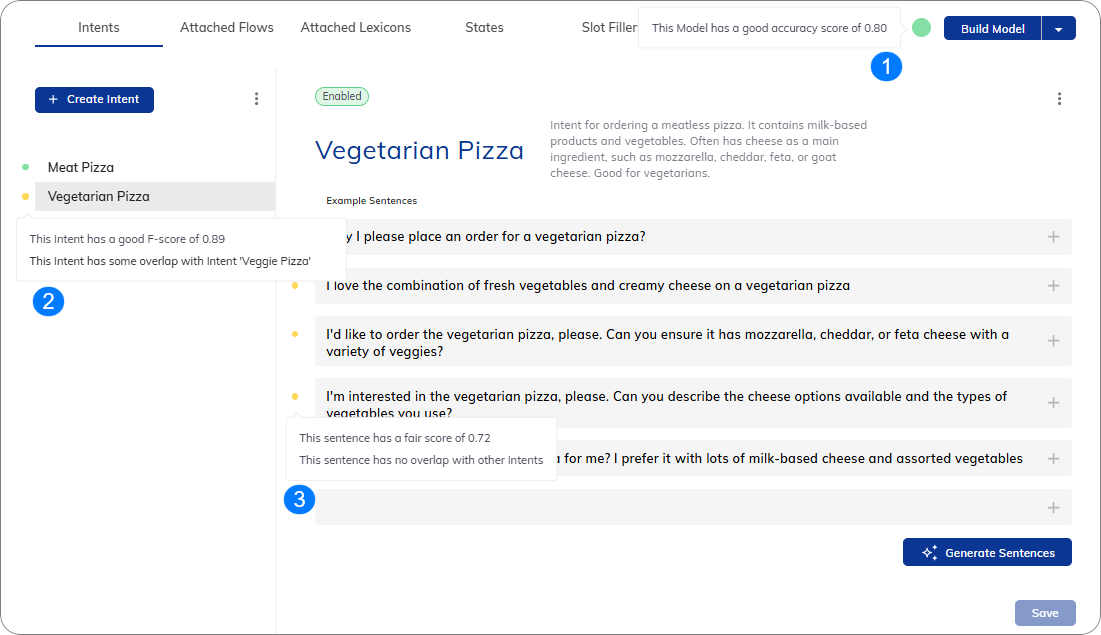
The Intent Analyzer assesses three main components:- Overall Intent Model — shows a total score for the NLU model’s quality.
- Individual Intent — shows scores for each Intent, which reflect how well the NLU model recognizes them and if they overlap with other Intents. You will see the NLU score along with names of any overlapping Intents.
- Individual Example Sentence — each example sentence receives a score based on how effective it is within the NLU model. You can see the score and any overlapping Intents by hovering over the traffic light in the interface.
How to Test
You can test NLU scores using the following interfaces:- GUI
- API
In the Interaction Panel, activate the debug mode feature and explore the detailed results in the
input.nlu.intentMapperResults.scores object.